Edit-Distanz (Levenshtein-Distanz)
Die Levenshtein-Distanz misst, wie unterschiedlich zwei Zeichenketten sind. Genauer gesagt gibt sie die minimale Anzahl von elementaren Operationen an, die notwendig sind, um eine Zeichenkette in eine andere zu überführen. Dabei sind drei Operationen erlaubt:
- Einfügen eines Zeichens;
- Löschen eines Zeichens;
- Ersetzen eines Zeichens.
Dieses Konzept spielt eine zentrale Rolle in der Informatik, insbesondere bei der Verarbeitung von Texten. Ein typisches Anwendungsbeispiel sind Rechtschreibkorrekturen: Hier wird die Distanz genutzt, um ähnliche Wörter zu erkennen und passende Vorschläge zu machen.
Die Berechnung erfolgt mithilfe eines Verfahrens aus der dynamischen Programmierung. Dazu wird eine Matrix aufgebaut, in der jede Zelle angibt, wie viele Operationen mindestens erforderlich sind, um ein Präfix der ersten Zeichenkette in ein Präfix der zweiten umzuwandeln.
Im Unterschied zur Hamming-Distanz funktioniert die Levenshtein-Distanz auch bei Zeichenketten unterschiedlicher Länge.
Beispiel
Betrachten wir die Zeichenketten \( s \) und \( t \):
$$ s = "kitten" $$
$$ t = "sitting" $$
Wir wollen bestimmen, wie viele Bearbeitungsschritte notwendig sind, um „kitten“ in „sitting“ zu überführen.
- Ersetzung
\( k \) wird durch \( s \) ersetzt: $$ "kitten" \rightarrow "sitten" $$ - Ersetzung
\( e \) wird durch \( i \) ersetzt: $$ "sitten" \rightarrow "sittin" $$ - Einfügung
Am Ende wird ein \( g \) eingefügt: $$ "sittin" \rightarrow "sitting" $$
Es sind also insgesamt drei Operationen nötig. Die Levenshtein-Distanz zwischen „kitten“ und „sitting“ beträgt damit 3.
Um dieses Verfahren systematisch umzusetzen, konstruiert man eine Matrix der Größe \( (m+1) \times (n+1) \), wobei \( m \) die Länge von „kitten“ (6) und \( n \) die Länge von „sitting“ (7) ist.
Eine zusätzliche Zeile und Spalte ermöglichen es, auch Transformationen von und zur leeren Zeichenkette zu berücksichtigen.
| "" | s | i | t | t | i | n | g | |
|---|---|---|---|---|---|---|---|---|
| "" | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| k | 1 | |||||||
| i | 2 | |||||||
| t | 3 | |||||||
| t | 4 | |||||||
| e | 5 | |||||||
| n | 6 |
Die Zelle \( (0, j) \) gibt an, wie viele Schritte notwendig sind, um eine leere Zeichenkette in das Präfix von „sitting“ der Länge \( j \) zu überführen. Diese Werte steigen von 0 bis 7.
Die Zelle \( (i, 0) \) beschreibt umgekehrt die Kosten, um das Präfix von „kitten“ der Länge \( i \) in eine leere Zeichenkette zu transformieren. Diese Werte reichen von 0 bis 6.
Für jede Zelle \( (i, j) \) wird der minimale Wert aus drei Möglichkeiten bestimmt:
- Löschen eines Zeichens aus „kitten“ (Wert der oberen Zelle plus \( 1 \));
- Einfügen eines Zeichens in „kitten“ (Wert der linken Zelle plus \( 1 \));
- Ersetzen eines Zeichens (Wert der diagonalen Zelle). Sind die Zeichen identisch, entstehen keine zusätzlichen Kosten.
Nun wird die Matrix Schritt für Schritt vollständig ausgefüllt:
| "" | s | i | t | t | i | n | g | |
|---|---|---|---|---|---|---|---|---|
| "" | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| k | 1 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| i | 2 | 2 | 1 | 2 | 3 | 4 | 5 | 6 |
| t | 3 | 3 | 2 | 1 | 2 | 3 | 4 | 5 |
| t | 4 | 4 | 3 | 2 | 1 | 2 | 3 | 4 |
| e | 5 | 5 | 4 | 3 | 2 | 2 | 3 | 4 |
| n | 6 | 6 | 5 | 4 | 3 | 3 | 2 | 3 |
Die erste Zeile zeigt, wie viele Schritte nötig sind, um aus einer leeren Zeichenkette schrittweise „s“, „si“, „sit“ usw. zu erzeugen. Für jedes zusätzliche Zeichen kommt genau eine Operation hinzu.
Die erste Spalte beschreibt die umgekehrte Situation: Wie viele Schritte erforderlich sind, um „k“, „ki“, „kit“ usw. in die leere Zeichenkette zu überführen. Auch hier erhöht sich der Aufwand mit jedem entfernten Zeichen um eins.
- Die Zelle (1,1) beschreibt die Umwandlung von „k“ in „s“. Der Wert ist 1, da genau eine Ersetzung notwendig ist.
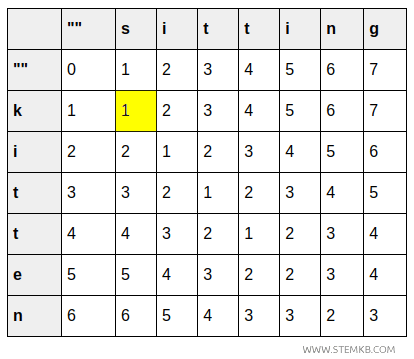
- Die Zelle (2,2) steht für die Transformation von „ki“ in „si“. Der Wert bleibt 1, da das zweite Zeichen identisch ist.
- Die Zelle (3,3) zeigt die Umwandlung von „kit“ in „sit“. Auch hier bleibt der Wert unverändert, weil sich das dritte Zeichen nicht ändert.
- Die Zelle (4,4) beschreibt die Transformation von „kitt“ in „sitt“. Der Wert bleibt weiterhin 1.
- Die Zelle (5,5) hat den Wert 2, da eine zusätzliche Ersetzung erforderlich ist, nämlich \( e \rightarrow i \).
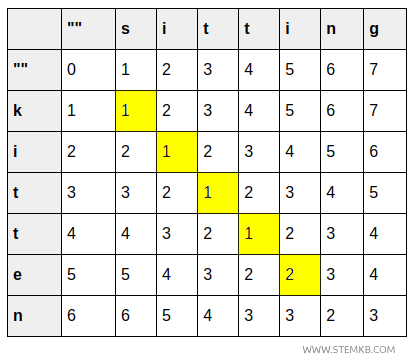
- Die Zelle (6,6) entspricht der Transformation von „kitten“ in „sittin“. Der Wert bleibt bei 2.
- Die Zelle (6,7) enthält schließlich den Wert 3. Hier wird zusätzlich ein \( g \) am Ende eingefügt.
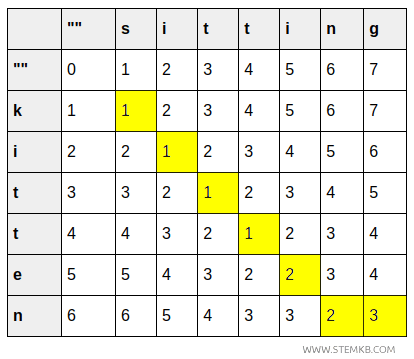
Die untere rechte Zelle \( (6,7) \) enthält das Endergebnis: Sie gibt die minimale Anzahl von Operationen an, um „kitten“ in „sitting“ zu überführen. Der Wert ist 3.
Dieses Ergebnis entspricht genau der Levenshtein-Distanz: zwei Ersetzungen und eine Einfügung.
Topologie der Levenshtein-Distanz
Die Levenshtein-Distanz ist nicht nur ein praktisches Werkzeug, sondern auch ein mathematisch sauberes Konzept. Sie definiert auf der Menge aller Zeichenketten einen metrischen Raum, da sie die grundlegenden Eigenschaften einer Metrik erfüllt.
- Nichtnegativität: Für alle \( x, y \) gilt \( D_L(x, y) \ge 0 \). Außerdem ist \( D_L(x, y) = 0 \) genau dann, wenn beide Zeichenketten identisch sind.
- Symmetrie: Es gilt \( D_L(x, y) = D_L(y, x) \). Die Reihenfolge spielt also keine Rolle.
- Dreiecksungleichung: Für alle \( x, y, z \) gilt \( D_L(x, z) \le D_L(x, y) + D_L(y, z) \).
Diese Eigenschaften machen die Levenshtein-Distanz zu einer echten Metrik.
Damit lässt sich auch eine metrische Struktur und eine zugehörige Topologie definieren.
Eine zentrale Rolle spielen dabei die offenen Kugeln. Für eine Zeichenkette \( x \) und einen Radius \( r \) ist die offene Kugel definiert als:
$$ B(x, r) = \{ y \mid D_L(x, y) < r \} $$
Sie enthält alle Zeichenketten, die „nahe genug“ bei \( x \) liegen.
Dieses Konzept ist besonders nützlich in Anwendungen wie der Rechtschreibkorrektur: Wörter mit kleiner Distanz zu einem gegebenen Begriff werden als mögliche Korrekturen vorgeschlagen.
Beispiel
Betrachten wir die Menge:
$$ X = \{"cat", "bat", "cut"\} $$
Wir untersuchen offene Kugeln mit Radius \( r = 2 \):
$$ B(x, 2) = \{ y \mid D_L(x, y) < 2 \} $$
Das bedeutet: Wir betrachten alle Zeichenketten, die sich höchstens um ein Zeichen unterscheiden.
- Zentrum "cat"
$$ B("cat", 2) = \{"cat", "bat"\} $$ - Zentrum "bat"
$$ B("bat", 2) = \{"bat", "cat"\} $$ - Zentrum "cut"
$$ B("cut", 2) = \{"cut"\} $$
Diese Mengen bilden eine Basis der Topologie.
Alle offenen Mengen entstehen als Vereinigungen solcher Kugeln.
Zum Beispiel:
$$ B("bat", 1) \cup B("cut", 1) = \{"cat", "bat", "cut"\} $$
Auch diese Menge ist offen.
So erhält man eine metrische Topologie auf \( X \), in der sich Nähe und Ähnlichkeit formal beschreiben lassen.



