Distanța Levenshtein
Distanța Levenshtein dintre două șiruri de caractere reprezintă numărul minim de operații elementare necesare pentru a transforma un șir în celălalt. Operațiile permise sunt:
- inserarea unui caracter;
- ștergerea unui caracter;
- substituirea unui caracter.
Distanța Levenshtein este una dintre cele mai utilizate metode pentru a măsura cât de asemănătoare sunt două șiruri de caractere. O regăsim în numeroase aplicații practice, de la corectoare ortografice până la motoare de căutare sau sisteme de recunoaștere a textului.
Ideea de bază este simplă: cu cât sunt necesare mai puține modificări pentru a transforma un șir în altul, cu atât cele două șiruri sunt mai asemănătoare.
Calculul se face prin construirea unei matrici, în care fiecare celulă conține costul minim necesar pentru a transforma un prefix al primului șir într-un prefix al celui de-al doilea. Valoarea finală, aflată în colțul din dreapta jos al matricii, reprezintă distanța Levenshtein.
Spre deosebire de distanța Hamming, distanța Levenshtein poate fi aplicată și șirurilor de lungimi diferite.
Exemplu concret
Considerăm șirurile \( s \) și \( t \):
$$ s = "kitten" $$
$$ t = "sitting" $$
Determinăm distanța Levenshtein dintre aceste două cuvinte, adică numărul minim de editări (inserări, ștergeri sau substituiri) necesare pentru a transforma „kitten" în „sitting".
- Substituire
Înlocuim \( k \) cu \( s \): $$ "kitten" \rightarrow "sitten" $$ - Substituire
Înlocuim \( e \) cu \( i \): $$ "sitten" \rightarrow "sittin" $$ - Inserare
Adăugăm \( g \) la finalul șirului: $$ "sittin" \rightarrow "sitting" $$
În acest caz sunt necesare trei operații (două substituiri și o inserare), deci distanța Levenshtein dintre „kitten" și „sitting" este 3.
Pentru a înțelege cum se obține acest rezultat în mod sistematic, construim o matrice de dimensiuni \( (m+1) \times (n+1) \), unde \( m \) este lungimea șirului „kitten" (6), iar \( n \) este lungimea șirului „sitting" (7).
Se adaugă o linie și o coloană suplimentare pentru a include și cazul șirului vid.
| "" | s | i | t | t | i | n | g | |
|---|---|---|---|---|---|---|---|---|
| "" | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| k | 1 | |||||||
| i | 2 | |||||||
| t | 3 | |||||||
| t | 4 | |||||||
| e | 5 | |||||||
| n | 6 |
Prima linie \( (0, j) \) reprezintă costul transformării șirului vid în prefixe ale șirului „sitting"; valorile cresc progresiv de la 0 la 7.
Prima coloană \( (i, 0) \) reprezintă costul transformării prefixelor șirului „kitten" într-un șir vid; valorile cresc de la 0 la 6.
Pentru fiecare celulă \( (i, j) \), costul minim se calculează alegând cea mai convenabilă dintre următoarele operații:
- ștergerea unui caracter din „kitten" (valoarea de deasupra + 1);
- inserarea unui caracter în „kitten" (valoarea din stânga + 1);
- substituirea unui caracter (valoarea diagonalei); dacă caracterele coincid, costul este 0.
Prin completarea acestei matrici pas cu pas se obține, în final, distanța Levenshtein dintre cele două șiruri.
Completăm acum matricea pas cu pas:
| "" | s | i | t | t | i | n | g | |
|---|---|---|---|---|---|---|---|---|
| "" | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| k | 1 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| i | 2 | 2 | 1 | 2 | 3 | 4 | 5 | 6 |
| t | 3 | 3 | 2 | 1 | 2 | 3 | 4 | 5 |
| t | 4 | 4 | 3 | 2 | 1 | 2 | 3 | 4 |
| e | 5 | 5 | 4 | 3 | 2 | 2 | 3 | 4 |
| n | 6 | 6 | 5 | 4 | 3 | 3 | 2 | 3 |
Observăm că fiecare celulă conține costul minim necesar pentru a transforma un prefix al cuvântului „kitten" într-un prefix al cuvântului „sitting". Matricea este completată progresiv, folosind rezultatele deja calculate.
De exemplu, transformarea șirului vid în „s", „si", „sit" și așa mai departe necesită câte o operație suplimentară pentru fiecare caracter adăugat.
În mod similar, transformarea șirurilor „k", „ki", „kit" într-un șir vid implică eliminarea succesivă a caracterelor, cu un cost care crește treptat.
- Celula (1,1) indică transformarea lui „k" în „s": costul este 1, deoarece este necesară o singură substituire.
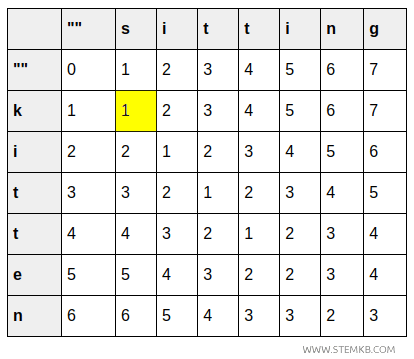
- Celula (2,2) arată transformarea lui „ki" în „si": costul rămâne 1, deoarece al doilea caracter este identic.
- Celula (3,3) descrie transformarea lui „kit" în „sit": costul este tot 1, întrucât caracterul „t" coincide.
- Celula (4,4) indică transformarea lui „kitt" în „sitt": costul rămâne 1, deoarece nu apare nicio modificare la acest pas.
- Celula (5,5) are valoarea 2 pentru transformarea lui „kitte" în „sitti", fiind necesară o substituire (e→i).
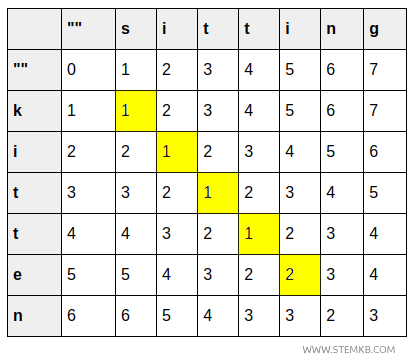
- Celula (6,6) indică transformarea lui „kitten" în „sittin": costul rămâne 2, deoarece ultimul caracter este deja corect.
- Celula (6,7) oferă rezultatul final: costul devine 3, deoarece trebuie inserat caracterul „g" la final.
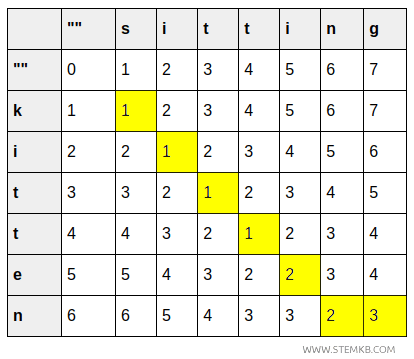
Ajungem astfel la celula finală, care conține costul total acumulat.
Valoarea din colțul din dreapta jos \( (6,7) \) reprezintă distanța Levenshtein dintre „kitten" și „sitting": 3.
Acest rezultat confirmă analiza directă: sunt necesare două substituiri și o inserare.
Topologia indusă de distanța Levenshtein
Distanța Levenshtein nu este doar un instrument practic, ci și un obiect matematic riguros. Ea definește o metrică pe mulțimea șirurilor de caractere.
Mai precis, această distanță satisface trei proprietăți fundamentale:
- Non-negativitate: pentru orice șiruri \( x \) și \( y \), avem \( D_L(x, y) \ge 0 \), iar \( D_L(x, y) = 0 \) doar dacă cele două șiruri sunt identice.
- Simetrie: \( D_L(x, y) = D_L(y, x) \). Transformarea din \( x \) în \( y \) necesită același număr de operații ca transformarea inversă.
- Inegalitatea triunghiulară: pentru orice \( x, y, z \), relația \( D_L(x, z) \le D_L(x, y) + D_L(y, z) \) este întotdeauna verificată.
Prin urmare, distanța Levenshtein definește un spațiu metric pe mulțimea șirurilor de caractere.
Din această perspectivă, putem introduce și topologia metrică indusă, care descrie formal noțiunea de apropiere între șiruri.
Pentru un șir \( x \) și o rază \( r \), bila deschisă centrată în \( x \) este definită prin:
$$ B(x, r) = \{ y \mid D_L(x, y) < r \} $$
Aceste bile deschise formează o bază a topologiei.
Acest cadru este esențial în aplicațiile în care trebuie să identificăm șiruri „apropiate". De exemplu, într-un corector ortografic, cuvintele aflate la o distanță mică față de un termen introdus pot fi propuse ca sugestii.
În acest mod, șirurile devin puncte într-un spațiu metric, iar distanța Levenshtein oferă un criteriu clar pentru a măsura apropierea dintre ele.
Exemplu
Considerăm mulțimea:
$$ X = \{"cat", "bat", "cut"\} $$
Construim bile deschise de rază \( r = 2 \) în jurul fiecărui element:
$$ B(x, 2) = \{ y \mid D_L(x, y) < 2 \} $$
Acestea conțin toate șirurile care diferă printr-o singură modificare.
Observație: deoarece folosim inegalitatea strictă, sunt incluse doar șirurile aflate la distanță mai mică decât 2. Pentru a include și cazul limită, am folosi $$ C(x, 2) = \{ y \mid D_L(x, y) \le 2 \} $$
- Bila centrată în "cat" $$ B("cat", 2) = {"cat", "bat"} $$
- Bila centrată în "bat" $$ B("bat", 2) = {"bat", "cat"} $$
- Bila centrată în "cut" $$ B("cut", 2) = {"cut"} $$
Aceste mulțimi formează o bază a topologiei.
Orice mulțime deschisă poate fi obținută ca reuniune a acestor bile.
De exemplu:
$$ B("bat", 1) \cup B("cut", 1) = {"cat", "bat", "cut"} $$
Prin această construcție, obținem o topologie metrică pe \( X \), în care apropierea dintre șiruri este descrisă riguros prin distanța Levenshtein.



