Distância de edição de Levenshtein
A distância de edição de Levenshtein mede quantas operações mínimas são necessárias para transformar uma cadeia de caracteres em outra. As operações permitidas são :
- inserir um caractere ;
- remover um caractere ;
- substituir um caractere.
Essa métrica é amplamente utilizada em áreas como correção ortográfica automática, motores de busca e processamento de linguagem natural. Sempre que é preciso comparar palavras ou sequências de texto, a distância de Levenshtein oferece uma forma simples e eficaz de medir o grau de semelhança.
O cálculo é feito por meio de uma matriz. Cada célula dessa matriz indica o custo mínimo para transformar um prefixo da primeira cadeia em um prefixo da segunda. A matriz é preenchida passo a passo, acumulando sempre o menor número possível de operações.
Ao contrário da distância de Hamming, a distância de edição de Levenshtein também pode ser aplicada a cadeias com comprimentos diferentes.
Exemplo concreto
Considere as cadeias \( s \) e \( t \) :
$$ s = "kitten" $$
$$ t = "sitting" $$
Queremos calcular a distância de edição de Levenshtein entre essas duas palavras, ou seja, o número mínimo de operações necessárias para transformar « kitten » em « sitting ».
- Substituição
Substituir \( k \) por \( s \) : $$ "kitten" \rightarrow "sitten" $$ - Substituição
Substituir \( e \) por \( i \) : $$ "sitten" \rightarrow "sittin" $$ - Inserção
Inserir um \( g \) no final da cadeia : $$ "sittin" \rightarrow "sitting" $$
São necessárias três operações no total. Portanto, a distância de edição de Levenshtein entre « kitten » e « sitting » é igual a 3.
Para representar esse processo, construímos uma matriz de dimensões \( (m+1) \times (n+1) \), onde \( m \) é o comprimento de « kitten » (6) e \( n \) o de « sitting » (7).
Adicionamos uma linha e uma coluna extras para incluir os casos em que uma das cadeias é vazia.
| "" | s | i | t | t | i | n | g | |
|---|---|---|---|---|---|---|---|---|
| "" | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| k | 1 | |||||||
| i | 2 | |||||||
| t | 3 | |||||||
| t | 4 | |||||||
| e | 5 | |||||||
| n | 6 |
A célula \( (0, j) \) representa o custo de transformar a cadeia vazia no prefixo de « sitting » com comprimento \( j \), que cresce de forma linear de 0 até 7.
De modo semelhante, a célula \( (i, 0) \) indica o custo de transformar o prefixo de « kitten » com comprimento \( i \) em uma cadeia vazia, variando de 0 até 6.
Para cada célula \( (i, j) \), escolhemos o menor custo entre três possibilidades :
- remover um caractere (célula superior +1) ;
- inserir um caractere (célula à esquerda +1) ;
- substituir um caractere (célula diagonal) ; se os caracteres forem iguais, não há custo adicional.
Preenchemos a matriz progressivamente, célula por célula :
| "" | s | i | t | t | i | n | g | |
|---|---|---|---|---|---|---|---|---|
| "" | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| k | 1 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| i | 2 | 2 | 1 | 2 | 3 | 4 | 5 | 6 |
| t | 3 | 3 | 2 | 1 | 2 | 3 | 4 | 5 |
| t | 4 | 4 | 3 | 2 | 1 | 2 | 3 | 4 |
| e | 5 | 5 | 4 | 3 | 2 | 2 | 3 | 4 |
| n | 6 | 6 | 5 | 4 | 3 | 3 | 2 | 3 |
Para entender melhor como funciona o cálculo, vamos observar como os custos evoluem dentro da matriz.
Por exemplo, transformar uma cadeia vazia em « s », « si », « sit », etc., exige uma operação adicional para cada caractere inserido. O custo cresce passo a passo, acompanhando o comprimento da cadeia.
De modo semelhante, transformar « k », « ki », « kit », etc., em uma cadeia vazia implica remover caracteres um a um, com um custo que aumenta de forma linear.
- A célula (1,1) representa a transformação de « k » em « s ». O custo é 1, pois basta uma única substituição.
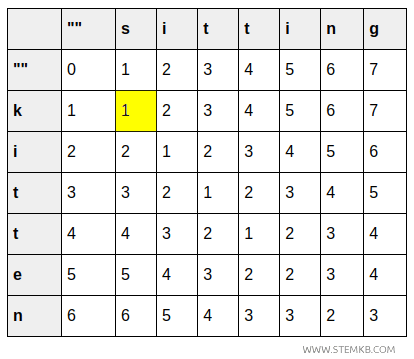
- A célula (2,2) corresponde à transformação de « ki » em « si ». O custo permanece 1, já que o segundo caractere (i) é o mesmo.
- A célula (3,3) indica o custo de passar de « kit » para « sit ». Continua sendo 1, porque o caractere (t) coincide.
- A célula (4,4) mostra a transformação de « kitt » em « sitt ». O custo ainda é 1, pois não há alteração no quarto caractere.
- A célula (5,5) apresenta custo 2 ao transformar « kitte » em « sitti », devido à substituição de \( e \) por \( i \).
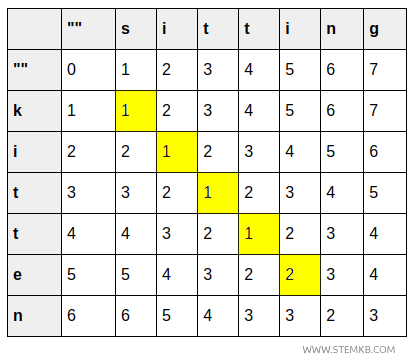
- A célula (6,6) representa a transformação de « kitten » em « sittin ». O custo permanece 2, pois o último caractere (n) não muda.
- A célula (6,7) mostra o passo final: transformar « kitten » em « sitting ». O custo total é 3, incluindo a inserção de um \( g \) no final.
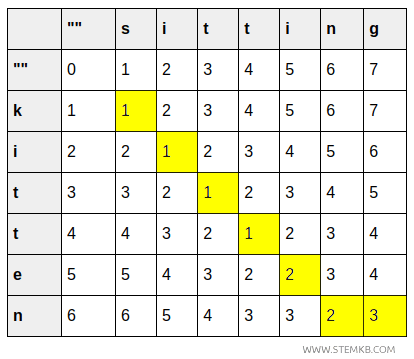
Chegamos, assim, à célula final da matriz, que contém o custo total acumulado.
A célula no canto inferior direito \( (6,7) \) fornece diretamente o resultado : o custo mínimo para transformar « kitten » em « sitting » é 3.
Esse valor corresponde exatamente à sequência mínima de operações : duas substituições e uma inserção.
Topologia induzida pela distância de Levenshtein
A distância de Levenshtein não é apenas uma ferramenta prática. Do ponto de vista matemático, ela define uma estrutura de espaço métrico no conjunto das cadeias de caracteres.
Isso acontece porque ela satisfaz as três propriedades fundamentais de qualquer métrica.
- Não negatividade
Para quaisquer cadeias \( x \) e \( y \), vale \( D_L(x, y) \geq 0 \), e \( D_L(x, y) = 0 \) somente quando \( x = y \). Ou seja, a distância só é nula quando as cadeias são idênticas. - Simetria
A distância é simétrica : \( D_L(x, y) = D_L(y, x) \). Transformar \( x \) em \( y \) exige o mesmo número de operações que transformar \( y \) em \( x \). - Desigualdade triangular
Vale sempre \( D_L(x, z) \leq D_L(x, y) + D_L(y, z) \). Em outras palavras, não existe “atalho” mais curto do que passar por uma cadeia intermediária.
Essas propriedades garantem que a distância de Levenshtein define um espaço métrico.
Como consequência, podemos associar a esse espaço uma topologia métrica induzida.
Dado um raio \( r \) e uma cadeia \( x \), define-se a bola aberta centrada em \( x \) como o conjunto das cadeias cuja distância a \( x \) é menor que \( r \) :
$$ B(x, r) = \{ y \mid D_L(x, y) < r \} $$
Essas bolas abertas formam a base da topologia induzida.
Essa estrutura é particularmente útil em aplicações práticas. Em sistemas de correção ortográfica, por exemplo, palavras próximas segundo a distância de Levenshtein são consideradas boas candidatas para sugestões de correção.
Nesse contexto, cada cadeia pode ser vista como um ponto, e a distância mede o quão “próximas” duas palavras estão.
Exemplo
Considere o conjunto \( X \) de cadeias com três caracteres :
$$ X = \{"cat", "bat", "cut"\} $$
Vamos analisar as bolas abertas de raio \( r = 2 \) :
$$ B(x, 2) = \{ y \mid D_L(x, y) < 2 \} $$
Isso significa que incluímos apenas cadeias que diferem por, no máximo, uma operação.
- Bola centrada em "cat"
$$ B("cat", 2) = \{"cat", "bat"\} $$ - Bola centrada em "bat"
$$ B("bat", 2) = \{"bat", "cat"\} $$ - Bola centrada em "cut"
$$ B("cut", 2) = \{"cut"\} $$
Esses conjuntos formam uma base da topologia induzida.
A partir deles, podemos construir todos os conjuntos abertos por meio de uniões.
Por exemplo :
$$ B("bat", 1) \cup B("cut", 1) $$
resulta em
$$ \{"cat", "bat", "cut"\} $$
que também é um aberto dessa topologia.
Dessa forma, a distância de Levenshtein não apenas mede diferenças entre cadeias, mas também permite estruturar o espaço das palavras de maneira rigorosa e útil para diversas aplicações.



